Best Practices
Train models without holding GPU
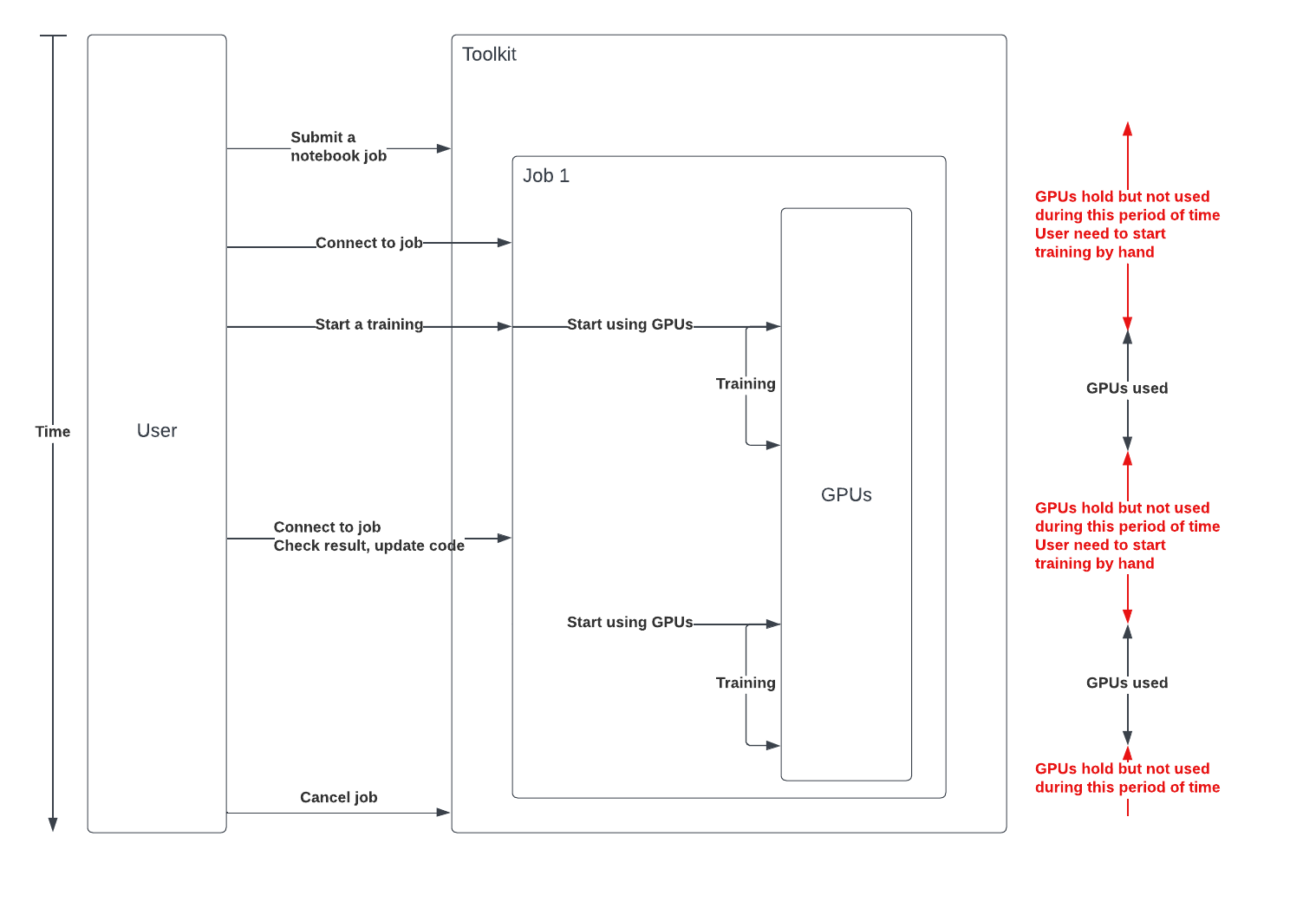
A bad way to train is to use a Jupyter Notebook to start your training. If your job is Restartable, the notebook could be preempted and restarted and the training will not be restarted.
Jupyter Notebook should only be used for debugging purpose.
Note
Due to the high number of GPUs hold without usage, a Idle Job cleaner was put in place to cancel the job without CPU or GPU usage.
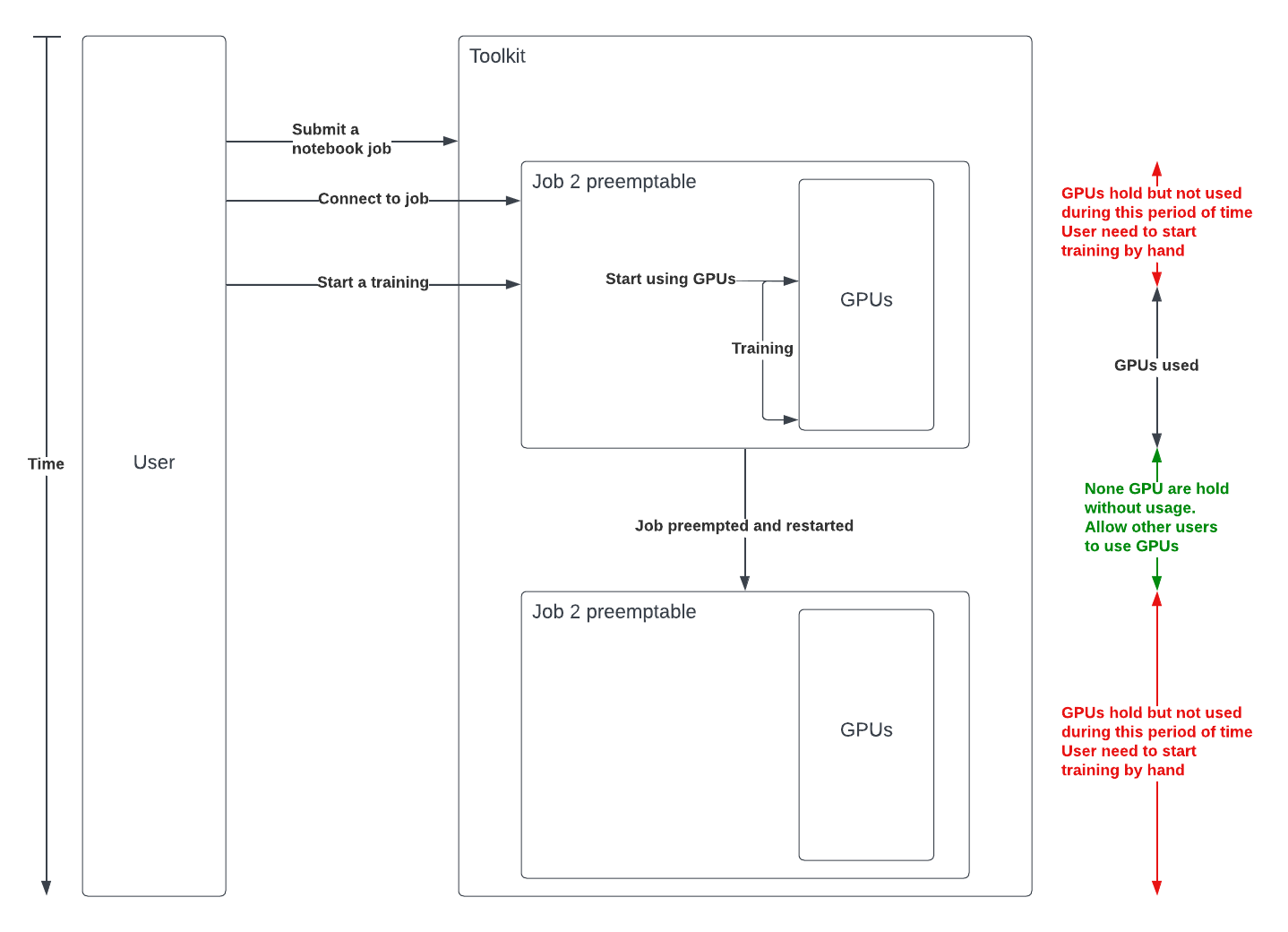
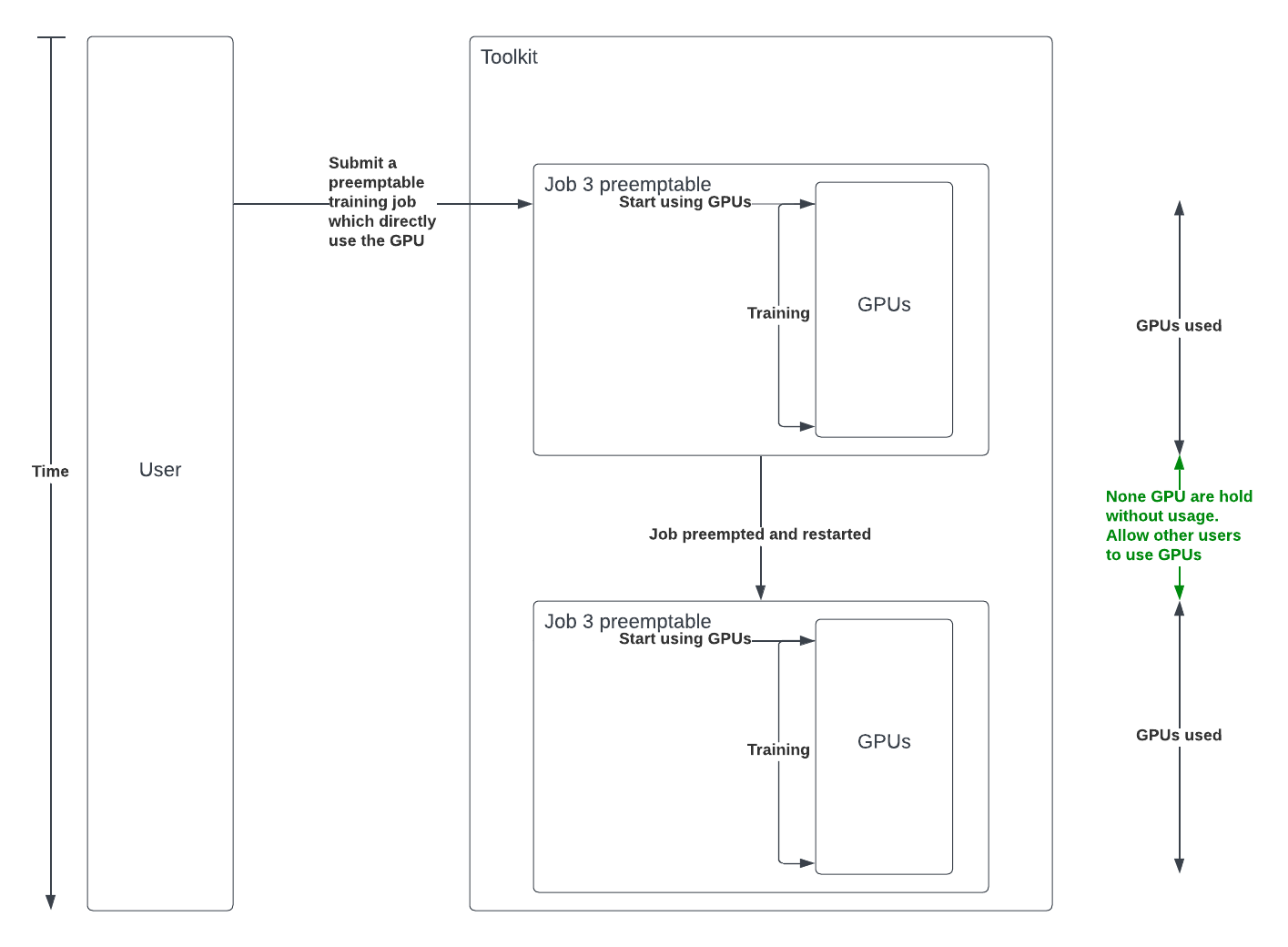
It is possible to train models without holding a GPU by using submitting jobs which will directly start or resume the training.

Checkpointing
Because there is a wide range of reasons why jobs can be interrupted at any given time, your jobs should create
checkpoints from which they can resume their task whenever they will get rescheduled. Once done, you should set the
restartable flag of those job.
Idempotence
An important quality of a well defined job is idempotence. Basically, it means that given the same input, a task will produce the same output. Implicitly, it means that an idempotent job will:
Always produce the same output from the same input
Put all temporary output in a private place
Not delete files that it didn’t create itself
Not overwrite any files (or atomically overwrite files with exactly the same content)
Not depend upon an unseeded random number
Not depend upon the system time
Not depend upon the value of Toolkit environment variables
Not depend upon external APIs, data or processes which aren’t versioned and idempotent themselves
Most machine learning training tasks can be trivially made idempotent, and there are tricks that can be used to ensure that even tasks that use a checkpoint are effectively idempotent.
Data home directory
A Toolkit data home is provided for each user. This is a private directory that can be used to store personal data like API keys, certificates, etc.
As a personal space, it will delete immediatelly when your account will be deleted.
Please, do not store models, dataset or any big files. Keep it under 10GB.
Please, do not create a data “home” in your account’s projects, otherwise your teammate will have to clean it for you.